A Resource-Efficient Text-to-Image Prior for Image Generations
Text-to-image (T2I) diffusion models, notably the unCLIP models (e.g., DALL-E-2), achieve state-of-the-art
(SOTA) performance on various compositional T2I benchmarks, at the cost of significant computational
resources.
The unCLIP stack comprises T2I prior and diffusion image decoder.
The T2I prior model alone adds a billion parameters compared to the Latent Diffusion Models, which
increases the computational and high-quality data requirements.
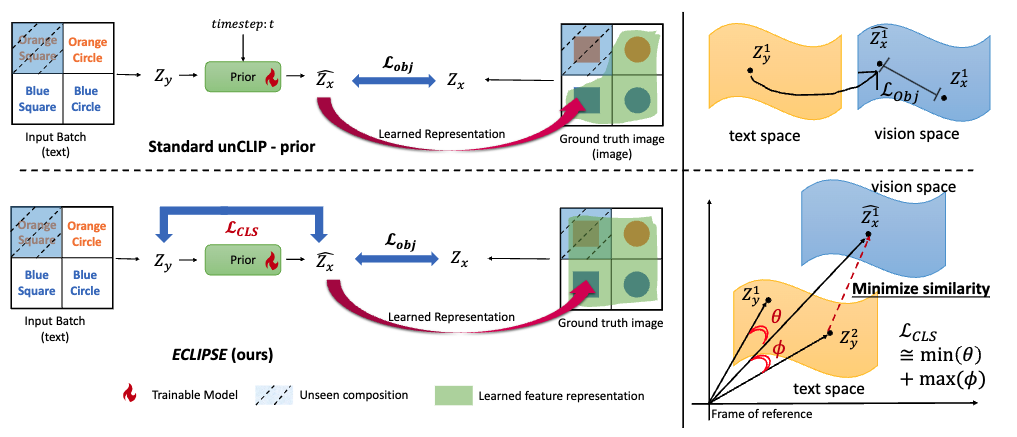
We introduce ECLIPSE, a novel contrastive
learning method that is both parameter and data-efficient.
ECLIPSE~leverages pre-trained vision-language models (e.g., CLIP)
to distill the knowledge into the prior
model.
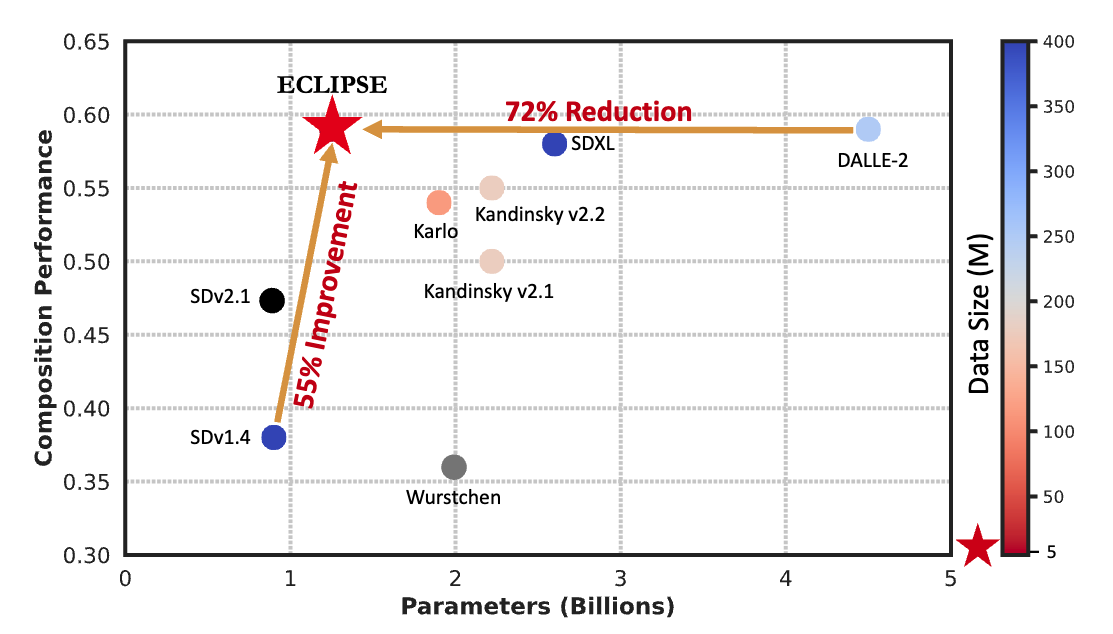
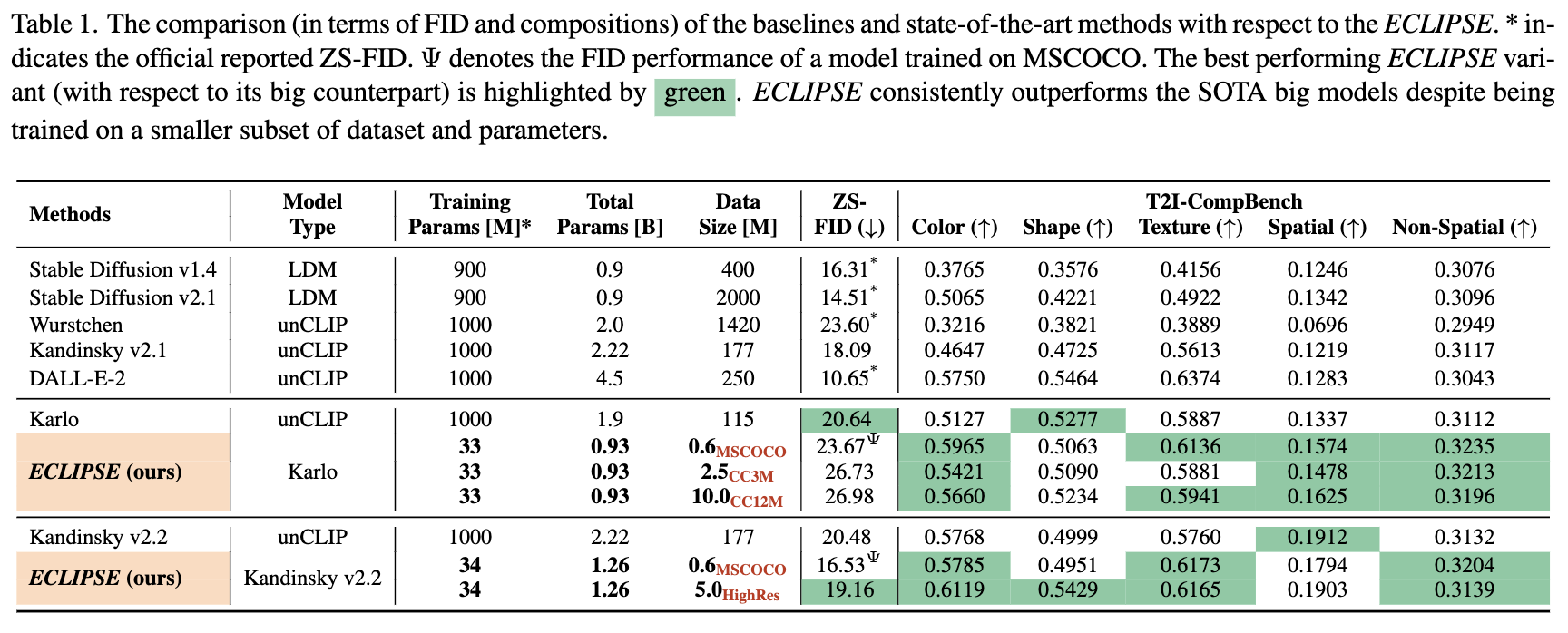
We demonstrate that the ECLIPSE~trained prior, with only 3.3% of
the parameters and trained on a mere
2.8% of the data, surpasses the baseline T2I priors with an average of 71.6% preference score under
resource-limited setting.
It also attains performance on par with SOTA larger models, achieving an average of 63.36% preference
score in terms of the ability to follow the text compositions.
Extensive experiments on two unCLIP diffusion image decoders, Karlo and Kandinsky,
affirm that ECLIPSE~consistently delivers high performance while
significantly reducing resource
dependency.

Weight Modulation for User Attribution and Fingerprinting in T2I Models.
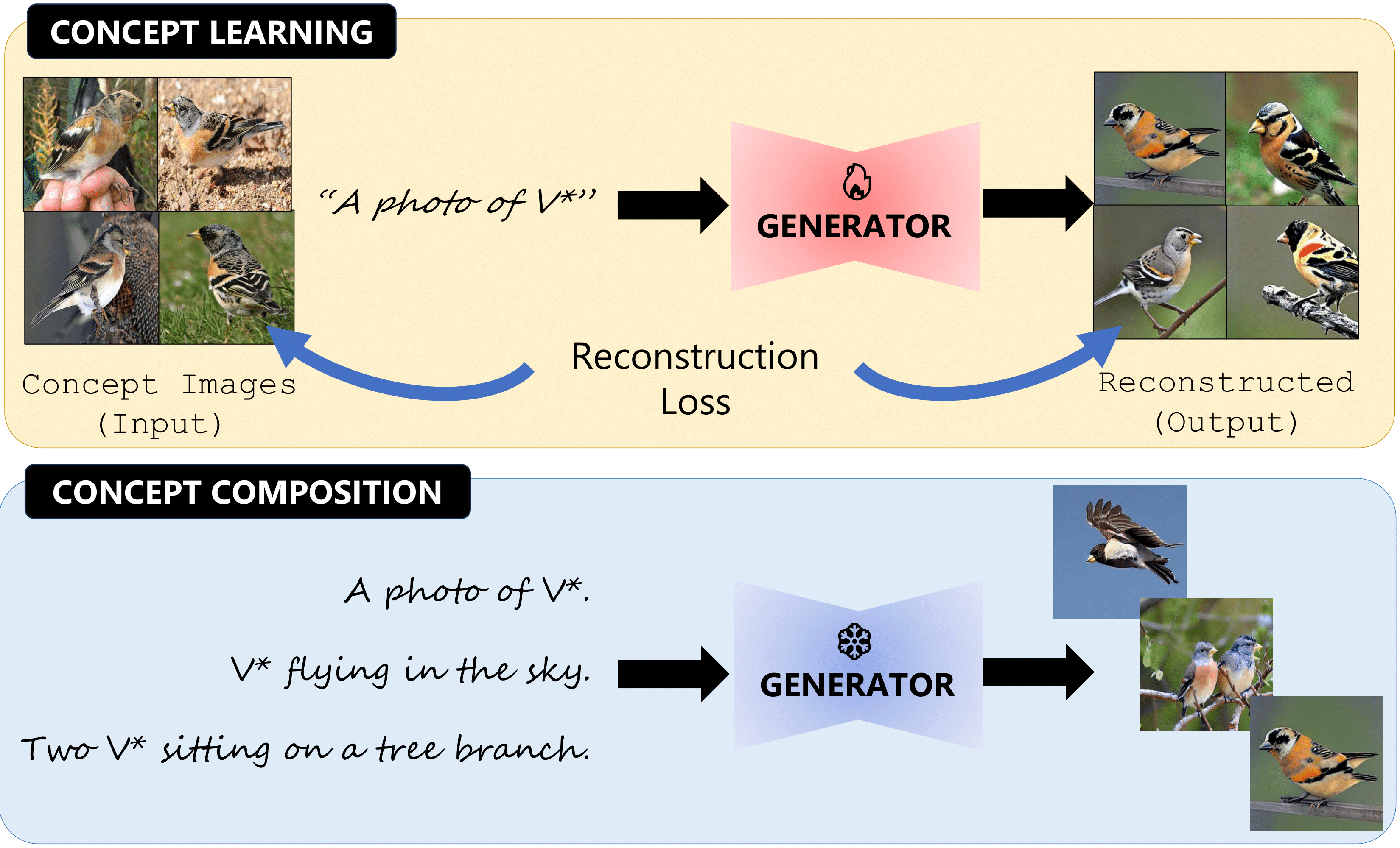
Evaluating Concept Learning Abilities of T2I Models